reentrance 를 우리말로 옮기자면 재진입성쯤 되고, thread-safety는
multithread-safety라고도 하니 다중쓰레드안전성쯤 되겠습니다. 요즘 워낙 multi-threaded
programming은 일반화된 것이라 thread-safety에 대해서는 어느 정도 개념들을 챙기고 계시리라 생각하고,
reentrance가 thread-safety와 어떻게 다른가를 설명하면서 그 둘간의 차이점을 설명해 보도록 하겠습니다.
어
떤 루틴 또는 프로그램이 Thread-safe하다라고 하면 여러 쓰레드에 의해 코드가 실행되더라도 실행 결과의
correctness가 보장되는 것을 뜻합니다. 이 정의에서 중요한 점은 실행 결과의 correctness가 보장되어야 한다는
것입니다. 즉, 여러 쓰레드에 의해 코드가 진짜로 동시에 수행되던 보이기에 동시에 수행되던 간에 실행 결과의
correctness가 보장되면 Thread-safe하다라고 말하는 거죠.
이에 비해 어떤 루틴 또는 프로그램이 Reentrant하다라고 하면 여러 쓰레드에 의해 코드가 동시에 수행될 수 있고, 그런 경우에도 실행 결과의 correctness가 보장되는 것을 뜻합니다.
이해가 되시나요 ? 차이점이 안 보이신다구요 ? 그럼 다시 한 번 말씀드리죠.
어떤 루틴 또는 프로그램이 Thread-safe하다라고 하면
여러 쓰레드에 의해 코드가 실행되더라도 실행 결과의 correctness가 보장되는 것을 뜻합니다.
이에 비해 어떤 루틴 또는 프로그램이 Reentrant하다라고 하면
여러 쓰레드가 코드를 동시에 수행할 수 있고, 그런 경우에도 실행 결과의 correctness가 보장되는 것을 뜻합니다.
이제 보이시죠 ? Reentrant 특성이 훨씬 강력한 제약조건이라는 것이 느껴지시나요 ? 구체적으로 코드에서는 어떻게 달라지나 예제를 통해서 알아보겠습니다.
C 언어 표준라이브러리에 strtok()이라는 문자열 함수가 있는 건 다 알고 계시겠죠(모르시는 분은 가서 엄마 젖 좀 더 먹고 오세요~ ㅋㅋㅋ 농담입니다). strtok() 의 매뉴얼에 다음과 같이 설명되어 있습니다.
The strtok() function can be used to break the string
pointed to by s1 into a sequence of tokens, each of which is
delimited by one or more characters from the string pointed
to by s2. The strtok() function considers the string s1 to
consist of a sequence of zero or more text tokens separated
by spans of one or more characters from the separator string
s2. The first call (with pointer s1 specified) returns a
pointer to the first character of the first token, and will
have written a null character into s1 immediately following
the returned token. The function keeps track of its position
in the string between separate calls, so that subsequent
calls (which must be made with the first argument being a
null pointer) will work through the string s1 immediately
following that token. In this way subsequent calls will work
through the string s1 until no tokens remain. The separator
string s2 may be different from call to call. When no token
remains in s1, a null pointer is returned.strtok()을 사용하는 예제를 보면 그 의미가 더 명확해집니다.
#include <cstring>
using namespace std;
int
main()
{
// strtok() 의 첫번째 argument 는 const char * 가 아닌 char * 이므로
// 새로 할당된 메모리로 넣음
char* str = (char*)malloc(strlen("A;B;C;D;E;F;G")+1);
strcpy(str, "A;B;C;D;E;F;G");
cout << str << " ==> ";
char* tok = strtok(str, ";");
while (tok != 0)
{
cout << tok << " ";
tok = strtok(0, ";");
}
cout << endl;
return 0;
}위
와 같이 작동한다는 것은 strtok() 내부적으로 다음과 같이 다음번 호출 때 문자열 분석을 시작할 위치를 기억하고 있다는 걸
뜻합니다. 그리고 여러번의 호출에 걸쳐 이 함수가 제대로 작동하기 위해서는 그 위치는 당연히 static 으로 선언되어 있겠지요.
char* strtok(char* src, const char* delim)
{
// src, delim 이 NULL 인지, delim 이 "" 인지 체크하는 코드는 생략
char* tok;
static char* next; // 분석을 시작할 위치
if (src != NULL)
next = src;
tok = next;
// boundary condition check
if (*next == '\0')
return NULL;
// 분석 시작
for (; *next != '\0'; ++next)
{
if (*next in delim) // pseudo code
{
*next = '\0';
++next;
break;
}
}
return tok;
}
위
와 같은 코드는 Reentrant 하지도 않고 Thread-Safe 하지도 않을 것입니다. 위 코드가 여러 쓰레드에 의해 수행될
경우, next 라는 변수가 서로 다른 쓰레드에 위해 공유가 되므로(함수 내에서 static으로 선언된 변수는 stack에
할당되는 것이 아니라 전역 메모리 영역에 할당됩니다) next 변수가 깨질 가능성이 생기기 때문입니다. 이런 상황에 대한
구체적인 예를 다음과 같이 들 수 있을 것 같습니다.
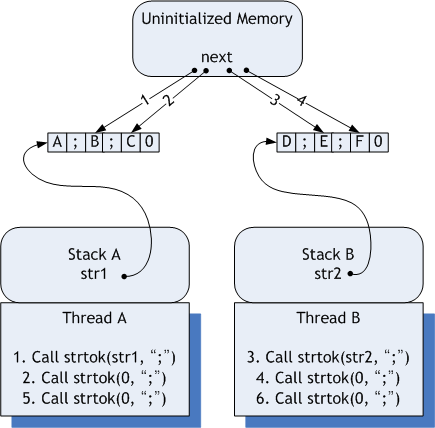
Multi-thread 상의 strtok() 호출
위
그림에서 Call strtok() 앞의 숫자는 호출 순서를 뜻하는 것이고 next가 가리키는 화살표의 선은 Call
strtok()을 호출한 후 next 변수의 상태값이라고 생각하시면 됩니다. 그림의 예에서는 3, 4 번까지는 원래 예상하는
결과 대로 리턴이 되겠지만 5번 호출에서는 "F"가 리턴될 것이고, 6번 호출에서는 NULL이 리턴될 것입니다(왜 그런지는 제가
작성한 strtok()을 따라가면서 알아보세요. ^^). 이런 결과가 나오는 것은 모두 next 라는 변수가 양쪽 Thread에
의해서 값이 갱신되기 때문입니다.
그렇다면 strtok()을 thread-safe 하게 만들기 위해서는 어떻게 해야할까요 ? 다음 처럼 strtok() 내부 구현을 바꿔서 내부적으로 next 변수에 대해 lock을 걸도록 만들면 될까요 ?
os_specific_lock lck;
char* strtok(char* src, const char* delim)
{
// src, delim 이 NULL 인지, delim 이 "" 인지 체크하는 코드는 생략
char* tok;
lock(&lck);
static char* next; // 분석을 시작할 위치
if (src != NULL)
next = src;
tok = next;
// boundary condition check
if (*next == '\0')
{
unlock(&lck);
return NULL;
}
// 분석 시작
......
unlock(&lck);
return tok;
}언
뜻 생각하면 위와 같이 구현된 strtok()이 thread-safe하다고 생각할 수도 있겠지만 실상은 전혀 그렇지 않습니다.
위와 같이 구현된 strtok()은 thread 가 동시에 next 변수를 수정하는 것을 막아주기 하지만 그림에서 나타낸 예를
제대로 처리해주지 못합니다. strtok()이 thread-safe 하기 위해서는 strtok() 호출 한번에 대해
thread-safe하면 되는 것이 아니라 전체 tokenizing 과정이 모두 thread-safe 해야 하기 때문입니다.
아~ 그렇군요. 그렇다면 tokenizing 과정 전체에 대해 lock을 걸면 되겠네요.
#include <cstring>
using namespace std;
os_specific_lock lck;
void* tokenizer(void* s)
{
char* str = (char*)s;
cout << str << " ==> ";
lock(&lck);
char* tok = strtok(str, ";");
while (tok != 0)
{
cout << tok << " ";
tok = strtok(0, ";");
}
unlock(&lck);
cout << endl;
return 0;
}
int
main()
{
pthread_t thr1, thr2;
char* str1, str2; // 어찌어찌해서 초기화됐다고 가정
pthread_create(&thr1, NULL, tokenizer, str1);
pthread_create(&thr2, NULL, tokenizer, str2);
return 0;
}
어
때요? 맘에 드시나요 ? tokenizing 과정 전체에 대해 lock을 걸어 버렸으니 제가 그림에서 제시한 상황이 발생하지
않겠네요. 그래도 어쩐지 꺼림직하지 않으세요 ? 마치 구더기 한 마리 잡으려고 불도저 쓰는 격이라고나 할까요. 위에 있는
tokenizer는 아주 간단해서 그렇지 만약에 token 하나 하나에 대해서 복잡한 처리를 한다면 어떻게 될까요 ? 그리고
복잡한 처리 과정 중에 그 쓰레드가 I/O 이벤트를 기다린다면 어떻게 될까요 ? 갈수록 태산이네요. 그죠 ? CPU가 아무리
빨라도 아무리 많은 Multi Core 들을 가지고 있어도 전혀 그런 성능을 활용하지 못하는 코드가 되어 버립니다. 이 사태를
어떻게 해결해야 하나요. 여러분이 진정한 엔지니어라면 여기서 멈춰서는 안돼죠. 해결책을 생각할 시간을 드리겠습니다.
1초.
2초.
3초.
4초.
5초.
6초.
7초.
8초.
9초.
10초 삐~~~~~!!!.
생각나셨나요 ? 멋진 해결책을 가지고 계신 분들이 있으리라 생각합니다. 자~ 그럼 다음과 같이 strtok() 인터페이스 및 구현을 바꾸면 어떨까요 ?
char* strtok(char* src, const char* delim, char** start)
{
// src, delim 이 NULL 인지, delim 이 "" 인지 체크하는 코드는 생략
char* tok;
char* next; // 분석을 시작할 위치. static 을 없애고 start 라는 입력
// 으로 초기화함
if (src != NULL)
next = src;
else
next = *start;
// boundary condition check
if (*next == '\0')
return NULL;
// 분석 시작
tok = next;
for (; *next != '\0'; ++next)
{
if (*next in delim) // pseudo code
{
*next = '\0';
++next;
break;
}
}
*start = next;
return tok;
}이
렇게 구현할 경우 thread-safe 하기도 하지만 reentrant하기도 합니다. 위와 같은 strtok() 내에서 사용되는
모든 변수는 stack에 할당되는 자동변수이므로 각각 독립적인 stack을 갖는 thread가 동시에 위와 같은
strtok()을 수행한다해도 전혀 문제가 없습니다. 실상 위와 같이 구현한 strtok()은 POSIX에 의해 표준화되어 있는
strtok_r()이나 MS Visual C++ 에서 제안한 safe string library에 표함되어 있는
strtok_s()와 동일합니다.
reentrant 한 코드는 thread 간에 공유하는 자원 자체가 없어야만 하는 코드입니다.
쓰레드간에 동기화 메커니즘 자체가 필요 없게 만드는 코드이고, 따라서 multi threading 환경에서 여러 쓰레드가 해당
코드를 진짜로 동시에 실행하더라도-동시에 실행되는 것처럼 보이기만 하는 것이 아니라-아무런 문제가 없습니다. 그렇지만
thread-safe 하다는 것은 단지 여러 쓰레드에 의해 실행되더라도 문제만 없으면 된다는 완화된 조건이므로 공유하는 자원이
있더라도 이것을 여러 쓰레드가 동시에 접근하지 못하도록 locking mechanism 같은 것으로 막아주기만 하면 됩니다.
결국 thread-safe한 코드는 multi threading 환경에서 reentrant 코드보다는 효율성이 떨어질 가능성이
높습니다. 해당 코드를 수행하고 있는 thread 가 공유 자원에 대한 lock 이 풀리기를 기다리는 동안은 다른 thread
의 수행을 막아버리기 때문입니다.
또 다른 간단한 예를 통해 thread-safe와 reentrant 의 차이점을 살펴 보겠습니다.
// 출처: Wikipedia
int g_var = 1;
int f()
{
g_var = g_var + 2;
return g_var;
}
int g()
{
return f() + 2;
}
위
와 같은 코드에서 g() 또는 f()를 호출하는 코드는 모두 thread-safe 하지 않습니다. thread-safe 하지
않으면 reentrant 하지도 않습니다. 위 코드를 thread-safe 하게 하려면 어떻게 해야할까요 ? 다음과 같이
해야겠죠.
int g_var = 1;
os_specific_lock lck;
int f()
{
lock(&lck);
g_var = g_var + 2;
unlock(&lck);
return g_var;
}
int g()
{
return f() + 2;
}
이
제 thread-safe하게 됐습니다. reentrant 할까요 ? 아니올시다입니다. 여러 쓰레드가 f() 함수를 동시에 수행할
수 없기 때문입니다. 다시 말하면 한 쓰레드가 lock 을 걸고 있다면 다른 쓰레드는 lock 이 풀릴 때까지 기다려야 하므로
reentrant 하지 않은 것입니다. 위 코드를 reentrant하게 고치려면 어떻게 하면 될까요 ?
// 출처: Wikipedia
int f(int i)
{
int priv = i;
priv = priv + 2;
return priv;
}
int g(int i)
{
int priv = i;
return f(priv) + 2;
}
아
예 전역 변수를 없애 버려서 쓰레드간 동기화가 필요 없게 만들어 버렸습니다. 위 코드에서는 워낙 lock이 걸리는 시간이 적을
것이므로 성능에 거의 영향을 미치지 않겠지만, lock이 걸리는 기간이 길어진다면 성능에 상당한 영향을 미치겠지요. 특히 요즘
유행하는 Multi-Core CPU에서는 그냥 thread-safe 코드와 reentrant 코드간의 성능 차이가 더 많이
발생할 것입니다.
보통은 thread-safe 코드를 만드는 것보다는 reentrant한 코드를 만드는 게 더
어렵습니다. 그리고, thread-safe 한 코드는 내부 구현만 바꾸면 되는 경우가 많지만 reentrant한 코드를 만드는
것은 위에서 제가 제시한 두 가지 예(strtok(), f())처럼 아예 인터페이스 자체를 재설계해야 하는 경우가 많습니다.
가
능하다면 그냥 thread-safe한 코드를 만드는 것보다는 reentrant한 코드를 만드는 것이 성능상 훨씬 좋은
선택입니다. 물론 reentrant 한 코드를 만드는 것이 불가능한 경우도 있겠지만, 고민해보면 reentrant한 코드를 만들
수 있는 경우가 상당히 있습니다. 요즘처럼 Multi-Core CPU가 갈수록 일반화되고 있는 상황에서 Reentrance는
다시 한 번 주목을 받아야 할 것입니다.
그럼 Coding Guideline스러운 멘트로 이번 글을 마무리 하도록 하겠습니다. ^^
"Thread-safe한 코드보다는 Reentrant한 코드로 작성하라"
출처 : http://yesarang.tistory.com/214







