





아래의 글들은 Xen과 KVM에 대한 관련 글들을 스크랩한 것입니다. 하지만, 문서의 정확한 소스 사이트를 알지 못하여 문서에 대한 원전을 기록하지 못하였습니다. 본 글의 저자에게 양해를 구합니다.
The news of KVM’s inclusion in the Linux kernel has me looking at KVM. How the virtualization layer is implemented has important ramifications, and KVM is much different from Xen. Xen
itself sits directly on the hardware and treats even your old OS as a
guest VM — for Xen, the Linux patches are necessary to make Linux a
guest VM on the hypervisor. It implements a model known as
paravirtualization that provides a lot of performance improvements over
other recent x86 virtualization techniques such as VMware’s. This model
includes a service VM that does privileged I/O work on behalf of the
guests. (In a following entry
I discuss some performance and efficiency issues, the larger story is
not so simple as “paravirtualization makes everything very fast”) Xen can also support unmodified guest VMs if you are using either a VT capable Intel processor or an SVM capable AMD processor. KVM is a patch to the Linux kernel that is more like VServer, Solaris containers,
or microkernels [see footnote], where the OS still sits directly on the
hardware. Some aspects of the current KVM release (mostly pulled from
their FAQ):
Xen vs. kernel containers: performance and efficiency
(This is part of a series of entries) Because
Xen and KVM both support unmodified guests, I’d speculate that in the
long run their raw CPU performance will converge on whatever concrete
limitation that hardware-assisted virtualization presents. And
paravirtualization may continue to reign here, or it may not. The
harder issues to think about are disk and network I/O. I
was part of an investigation into how to make resource guarantees for
workspaces under even the worst conditions on non-dedicated VMMs (Division of Labor: Tools for Growth and Scalability of Grids).
The amount of CPU needed to support the guests’ I/O work (what I like
to casually call the “on behalf of” work in the service domain) was
pretty high and we looked at how to measure what guarantees were needed
for the service domain itself to make sure the guest guarantees were
met. So we had to write code that would extrapolate the CPU
reservations needed across all domains (including the service domain). One
major source of the extra CPU work is context switching overhead, the
service domain needs to switch in to process pending I/O events (on
large SMPs, I’ve heard recommendations to just dedicate a CPU to the
service domain). Also, in networking’s case, the packets are zero copy
but they must still traverse the bridging stack in the service domain. One
important thing to consider for the long run on this issue is that
there is a lot of work being done to make slices of HW such as
Infiniband available directly to guest VMs, this will obviate the need
for a driver domain to context switch in. See High Performance VMM-Bypass I/O in Virtual Machines Container
based, kernelspace solutions offer a way out of a lot of this overhead
by being implemented directly in the kernel that is doing the “on
behalf of” work. They also take advantage of the resource management
code already in the Linux kernel. They
can more effectively schedule resources being used inside their regular
userspace right alongside the VMs (I’m assuming) — and more easily know
what kernel work should be “charged” to what process (I’m assuming).
These two things could prove useful, avoiding some of the monitoring
and juggling that is needed to correctly do that in a Xen environment
(see e.g., the Division of Labor paper mentioned above and the Xen related work from HP). There is an interesting paper Container-based Operating System Virtualization: A Scalable, High-performance Alternative to Hypervisors out of Princeton. The
authors contrast Xen and VServer and present cases where
hard-partitioning (that you find in Xen) breeds too much overhead for
grid and high performance use cases. Where full fault isolation and OS
heterogeneity are not needed, they advocate that the CPU overhead
issues of Xen I/O and VM context switches can be avoided. (The idea presented there of live updating the kernel (as you migrate the VM) is interesting. For jobs that take months (that will miss out on kernel updates to their template images) or services that should not be interrupted, this presents an interesting alternative for important security updates (though for Linux, I’m under the impression that security problems are far more of a problem in userspace). --------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Finally user-friendly virtualization for Linux
The
upcoming 2.6.20 Linux kernel is bringing a nice virtualization
framework for all virtualization fans out there. It's called KVM, short
for Kernel-based Virtual Machine. Not only is it user-friendly, but
also of high performance and very stable, even though it's not yet
officialy released. This article tries to explain how it all works, in
theory and practice, together with some simple benchmarks. A little bit of theory There
are several approaches to virtualization, today. One of them is a so
called paravirtualization, where the guest OS must be slightly modified
in order to run virtualized. The other method is called "full
virtualization", where the guest OS can run as it is, unmodified. It
has been said that full virtualization trades performance for
compatibility, because it's harder to accomplish good performance
without guest OS assisting in the process of virtualization. On the
other hand, recent processor developments tend to narrow that gap. Both
Intel (VT) and AMD (AMD-V)
latest processors have hardware support for virtualization, tending to
make paravirtualization not necessary. This is exactly what KVM is all
about, by adding virtualization capabilities to a standard Linux
kernel, we can enjoy all the fine-tuning work that has gone (and is
going) into the kernel, and bring that benefit into a virtualized
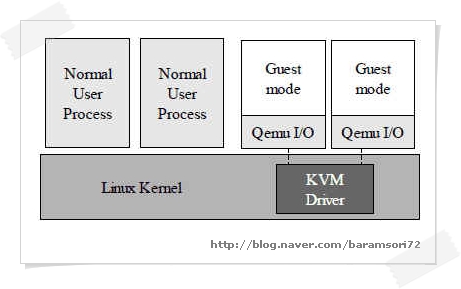
environment. Under
KVM's model, every virtual machine is a regular Linux process scheduled
by the standard Linux scheduler. A normal Linux process has two modes
of execution: kernel and user. KVM adds a third mode: guest mode (which
has its own kernel and user modes). KVM consists of two components:
QEMU is a well known processor emulator written by French computer wizard Fabrice Bellard. KVM in practice: Windows XP as a guest OS Although
KVM is still in development, I decided to play a little bit with it. I
used 2.6.20-rc2 kernel, together with already available Debian
packages: kvm and qemu.
So, after I have recompiled the kernel and installed packages,
everything was ready. I suppose that this, together with the fact than
no proprietary software or binary kernel modules is needed, explains
why I call it user-friendly. But, there's more, see how easy it's to install (proprietary!) guest OS: And
that's it, I suppose it doesn't get simpler than that, in short time I
had Windows installed and running. Why Windows, some of you may ask?
Well, I couldn't find a reason to have another Linux virtualized under
this one, at the moment. Also, I always wanted to have a handy
virtualized Windows environment for some experimental purposes. Not
dual-booting it, which is PITA for everyday use, but something that
could be easily started from time to time. For example to see how this
web page looks in IE7, and stuff like that...
OK,
so with Windows XP installed in no time, I had plenty of time left to
do some simple benchmarks. Nothing comprehensive or scientific, I
remind you, just a few quick tests so that you have rough idea how KVM
works in practice. I've also included few other interesting cases,
because it was easy to do. Once I had installed Windows OS, it could be
run even under unmodified QEMU, no problem. And with a little
additional effort I also compiled kqemu, QEMU accelerator module
written by QEMU's original author, unfortunately a closed-source
product. Finally, the choice of the applications that I ran has fallen
to only two of them, PCMark2002 and Super PI
(ver 1.1e) with the sole reason that I had numbers from those two
applications from the times when I had Windows XP installed natively
(but that was few months ago, and I have since deleted it). Before I
forget, the tests were run on an Intel E6600 processor. I
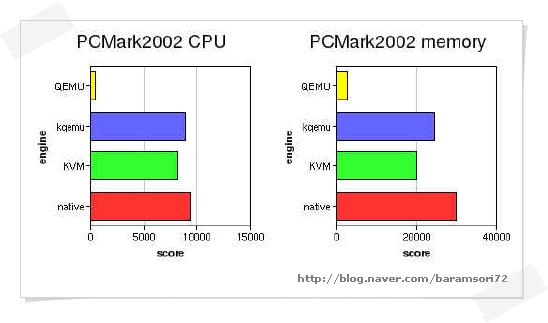
think it's pretty obvious how much improvement both kqemu and KVM bring
over QEMU emulator alone. Also, it seems that kqemu still commands a
slight lead over KVM, but I'm sure that KVM performance will only
improve over time, it's really young compared to all other
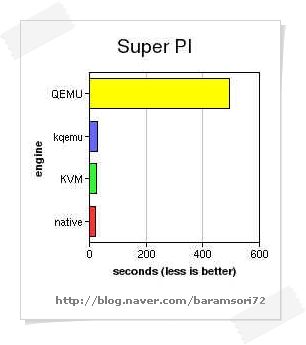
virtualization products. Running
Super PI is another story, KVM is the fastest one here, running at 84%
of the native speed, which is a great result. Stock QEMU is so slow at
this task, that graph above is hard to decipher, so I'll list all the
results here (time to generate first million digits of pi, less is
better): QEMU: 492.5 sec, kqemu: 28.5 sec, KVM: 25.5 sec, native: 21.5
sec.
While
still in the early development stages, KVM shows a real potential. It's
fun working with it, and I suppose we'll hear more and more good news
about it in the following months. At the time when this technology gets
incorporated in the mainstream Linux distributions (in not so distant
future) virtualization will become a real commodity. And not only for
data centers and server consolidation purposes, but also on Linux
desktops everywhere. Mostly thanks to a really great work on behalf of
QEMU & KVM developers. But, you can start playing with it today... Resources:
약어: KVM: Kernel-based Virtual Machine for Linux |
WRITTEN BY
- RootFriend
개인적으로... 나쁜 기억력에 도움되라고 만들게되었습니다.